Extracción automatizada de información del CNE usando Python

En esta oportunidad quiero compartir con ustedes un poco de código escrito en Python, con el que podemos raspar datos básicos que son de dominio público y están al alcance de todos en la web oficial del Consejo Nacional Electoral de Venezuela.
El Consejo Nacional Electoral (CNE) es la institución que rige el tema electoral en Venezuela, en su web oficial se puede consultar el nombre completo y en qué lugar le corresponde votar a una persona, conociendo su número de identidad conocido también como número de cédula o NIE.
Como respuesta, la web nos devuelve el nombre completo de la persona y los datos del centro de votación (Nombre, Estado, Municipio, Parroquia y dirección del centro electoral).
Cuando queremos realizar un par de consultas se puede realizar de forma manual directamente en la web de la institución, sin embargo cuando se trata de gran cantidad de datos debemos recurrir a las técnicas de Scraping a fin de hacernos de la información necesaria.
A continuación comento el código escrito en Python que nos va a permitir obtener la información del sitio web oficial del CNE haciendo uso de las técnicas de scraping.
busquedaCNE.py
Aun cuando creo que el código está suficientemente documentado, vamos a dar un poco más de detalle. Lo primero es importar las librerías que nos permitirán manipular el contenido HTML, para ello en la línea 3 importamos requests, a través de esta librería podemos realizar solicitudes a los servidores simulando la petición que realiza un usuario a través de un navegador web. En la línea 4 utilizamos Beautifulsoup de bs4, ambas no vienen por defecto en nuestra instalación de Python, para hacer uso de ellas es necesario instalar las librerías primero con el comando pip install bs4 requests desde la terminal.
1. # requiere python3
2.
3. import requests
4. from bs4 import BeautifulSoupNota: Enumero cada línea sólo como referencia para ser más explícito en esta documentación pero no tiene correlación numérica con el código fuente real.
url_semilla es una variable que almacena la url base, aún sin los parámetros necesarios para la consulta.
# Url destino
url_semilla = "http://www.cne.gob.ve/web/registro_electoral/ce.php?"Los valores como mencionamos anteriormente son la nacionalidad, que deberá ser un carácter en mayúscula V para ciudadano venezolano o E para ciudadanos extranjeros. Y la cédula, que es el número de identidad. Por ahora creo que rondan por el orden de los 30 millones, un número entero de hasta ocho (8) dígitos.
Parámetros a incluir en la url (Datos para el ejemplo)
nacionalidad = 'V'
cedula = '14147068'Para esta práctica vamos a usar datos estáticos, pero posteriormente lo haremos de forma dinámica. Ejemplo dinámico
Ya conociendo la url_semilla y los datos a consultar, construimos lo que yo denomino la url_compuesta, que es la url_semilla concatenada con los valores necesarios para realizar la consulta.
# Url final
url_compuesta = url_semilla + 'nacionalidad=' + nacionalidad + '&' + 'cedula=' + cedulaSe realiza la solicitud para obtener la respuesta almacenada en la variable requests del tipo requests.
# Petición
requests = requests.get(url_compuesta)Seguidamente, tomamos la respuesta que nos devuelve el servidor que tenemos almacenado en la variable requests y lo parseamos como html para asignarlo a la variable soup que será la que contendrá toda la estructura HTML
# Tomamos el requests, lo parseamos a html para obtener un tipo de dato soup
soup = BeautifulSoup(requests.content, "html.parser")Toda petición realizada a un servidor devuelve un código del estatus resultante de dicha solicitud, por ejemplo un código 404, bien sabido que hace referencia a una web no encontrada posiblemente movida a otra url o simplemente borrada y así otros tantos códigos. Pero a nosotros nos interesa validar que el estatus de nuestra solicitud sea 200. Ya que es el que nos indica que nuestra solicitud ha sido atendida correctamente, y en consecuencia tendremos en nuestra variable requests el contenido necesario para raspar con nuestro código.
1. # status_code 200 es OK, en caso contrario web no disponible e imprimimos mensaje y código de error
2. if requests.status_code == 200:
3. contenList = []
4.
5. for contenido in soup.find_all('td')[10: 24]:# 10:24 los <td> del árbol que nos interesa
6. dato = contenido.text
7. contenList.append(dato.strip())
8.
9. datosPersona = '\nCedula:' + contenList[1] + '\n' + 'Nombre y Apellido: ' + contenList[3]
10.
11. datosCentro = '\nEsdato:' + contenList[5] + '\n' + 'Municipio: ' + contenList[7]
12.
13. print(datosPersona + datosCentro)
14.
15. else:
16. print("Error de conexión: Codigo ", requests.status_code)Es por eso que en la línea 2 iniciamos una estructura condicional if — else que nos permita tomar dos cursos de acción, uno en el if cuando el código sea igual a 200 (solicitud exitosa) y un segundo curso de acción cuando el código sea distinto a 200, en tal caso, no fue posible acceder a la web y en consecuencia lanzamos un mensaje de error seguido del número del mismo.
Una vez dicho todo lo anterior solo nos queda centrarnos en la verdadera lógica y el corazón del código, que es cómo vamos a extraer la información de la web.
En la línea 3 declaro una lista vacía, en ella voy a almacenar los datos raspados.
En la línea 5 inicio un bucle for para recorrer la estructura HTML. Haciendo uso de la función find_all buscamos todas las etiquetas de tipo <td>, ya que previamente inspeccionamos la web y sabemos que los datos que nos interesan están dentro de unas etiquetas <td>.
Pero resulta que en el HTML hay varias etiquetas <td> de diferentes niveles, pero las que nos interesan están entre los niveles 10 y el 24. El resto de los niveles también contienen los datos pero con mucha “basura” o texto que no es de nuestro interés.
Al recorrer las etiquetas que se encuentra entre los niveles 10 al 24 tomará el contenido de dichas etiquetas y los almacenará en la variable contenido, posteriormente en la línea 6 extraemos de la variable contenido el texto y se lo asignamos a la variable dato.
En la línea 7 retiramos los espacios en blanco con el método strip() y lo agregamos a la lista que irá almacenando los datos de nuestro interés.
Datos resultantes de esta ejemplo:
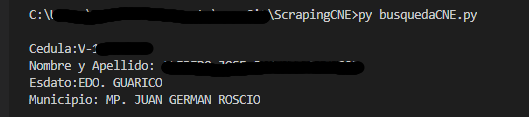
Espero les sea de utilidad, todo el código está disponible aquí y cualquier comentario de ustedes es muy valioso para mí.
